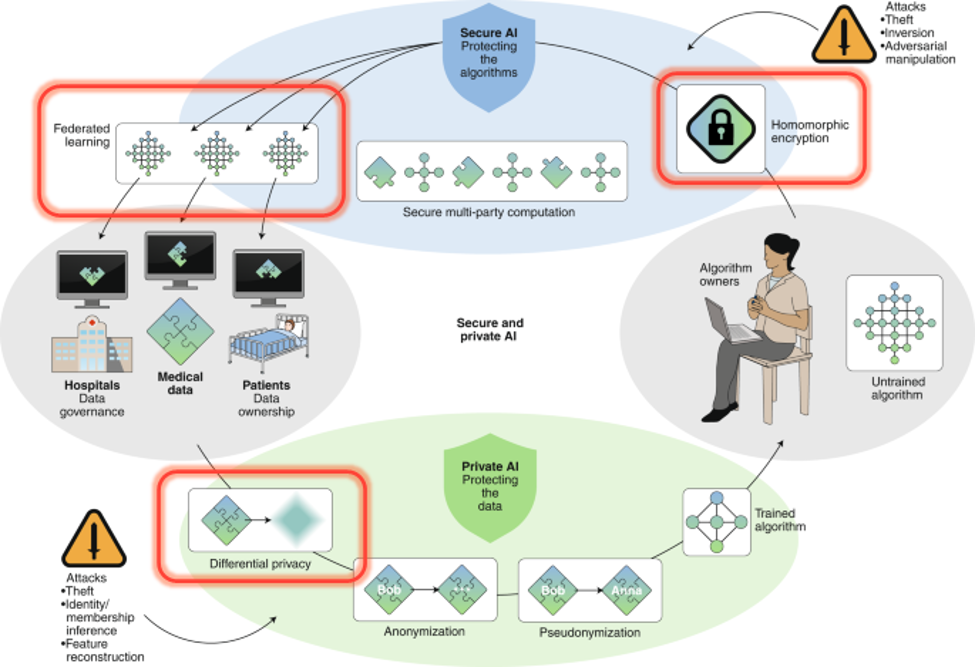
Tanulmányunk elején áttekintjük, hogy a biztonságos és privacy védő mesterséges intelligencia megoldások milyen kihívásokkal szembesülnek, illetve mik azok a az alapvető építőkövek, melyekre támaszkodva biztosítani lehet az adatok védelmét.
A „nagy kép” felvázolását követően három kiemelt módszert tárgyalunk. Ezek kiemelt szerepet kaphatnak egy biztonságos adatelemzési környezet kialakításában, ugyanakkor mindhárom új, nem triviális megközelítést hoz az adatelemzés területére. A három téma rendre a következő:
- Differenciált adatvédelem (DA) módszere – A technika alapgondolata, hogy a megosztásra kerülő adattagokat úgy módosítsuk (tipikusan úgy terheljük meg zajjal), hogy a módosított adatok birtokában a támadóknak kevés esélyük legyen az eredeti adatpontokra vonatkozó alapadatok visszafejtésére, miközben az eredeti elemzési célt mégis jól el tudjuk érni. Tipikus példája a területnek, mikor különböző statisztikákat kívánunk publikálni miközben vigyázni szeretnénk a kis elemszámú adatpontból számolt részstatisztikák adatszivárgása ellen.
- Federált gépi tanulási (FGT) algoritmusok – Ezen eljárások képesek úgy felépíteni gépi tanulási modelleket, hogy a tanító adathalmazok elosztottan vannak jelen az adattulajdonosoknál. A módszerrel úgy építhetők adatbányászati modellek, hogy az adatokat birtokló intézetek, felhasználók (például adatpénztárca tulajdonosok) az adataikat nem osztják meg az algoritmus futtatása során. Hasonló módon a módszerrel akár több pénzintézet építhet közös kockázati modelleket, miközben saját ügyfeleinek adatait az üzleti titok megtartása és a GDPR rendelkezéseknek megfelelően rejtve tudja tartani az együttműködő partnerek előtt.
- Homomorf titkosítás – Ennek a megközelítésnek az ideája szerint úgy rejtjük el az adatokat, hogy a feldolgozó algoritmusok műveletekeiket a titkosított adaton tudják, az eredeti adatokat nem látják. Ennek megvalósításához egy speciális homomorf titkosítási módszert használ, ami magas számítási kapacitás igény mellett képes biztosítani magas fokú adatbiztonságot, de jelentősen korlátozza a megvalósítható elemzési műveleteket. A módszer még kiforratlan, az első implementációkkal nemrég léptek elő a nagy szoftvergyártó cégek.
A módszerek többségéhez megfelelő implementációk is elérhetők már, de a megfelelő védelem biztosítása érdekében gyakran több módszer kombinálására van szükség. Összességében elmondható, hogy a privacy és az adatok védelme az adatelemzés területén komoly technológiai és szervezési kompetenciák felvonultatásával ma már jól megoldható.