A BME és az MNB szakértőiből álló kutatócsapat a természetes nyelvfeldolgozás (NLP) eszközeinek felhasználásával gazdasági idősorok és a gazdasági hírek kapcsolatát vizsgálja. A gazdasági portálok szövegeinek nyelvi elemzésén alapuló, mesterséges intelligenciát alkalmazó szövegfeldolgozás segítségével egy megfelelően nagy hírállomány szentiment elemzésére került sor, amelynek eredménye használható a piaci hangulatot mérő indexekhez hasonlóan a gazdasági mutatók (pl. GDP vagy akár a CPI) becslésének pontosításához, vagy akár azok pontosabb megértéséhez. Előnyük a befektetői és egyéb piaci hangulat-indexekhez képest, hogy jóval kisebb időkéséssel állnak rendelkezésre és nem tartalmaznak szelekciós torzítást.
Egy ilyen index létrehozásához azonban számos kihívással kellett szembenéznünk. Ezek közül említésre méltó saját címkézett adatbázisunk elkészítése, mely magyar nyelven a témában egyedülálló. Emellett kihívást jelentett még nagy mennyiségű szöveges adat gyors feldolgozása is, melyet a modern NLP eszközök alkalmazásával oldottunk meg.
Mesterséges intelligencia és a természetes nyelvfeldolgozás
Az elmúlt évtizedben a mélytanulás a természetes nyelvfeldolgozás (Natural Language Processing, NLP) egyik elsődleges eszközévé vált. Jelentős áttörést hozott a CBOW és skip-gram vektoros szóreprezentációk bevezetése 2013-ban. Ezen szóvektorok meglepően mély szemantikai tulajdonságokat hordoznak magukban – és egyben kimagasló eredményeket értek el szekvenciális mélytanuló modellek segítségével. A következő paradigmát a 2017-ben megjelent ún. transzformer hálózatok hozták el. A transzformer modell egyrészt alkalmas a szavak szövegkörnyezet-függő vektoros leírásának létrehozására, másrészt rendkívül jól skálázódnak mind tudásban, mind a számítások hatékonyságában: a millió paraméteres nagyságrendtől, a milliárdoson át a billiósig a mai nyelvi modellek mögött a transzformer architektúra van.
Kutatómunkánkban a nyelvi modelleket szentiment becslésre hangoltuk magyar gazdasági híreket és azok hangulatát tartalmazó címkézett szövegkorpusz alapján. A modellezést inkrementális módon végeztük, kezdve a kulcsszó számlálástól, a Word2Vec alapú megoldáson át a transzformer alapú BERT (Bidirectional Encoder Representations from Transformers) modellekig. Jelen bejegyzésünkben az utóbbi eredményeit mutatjuk be.
Gazdasági szentiment becslése

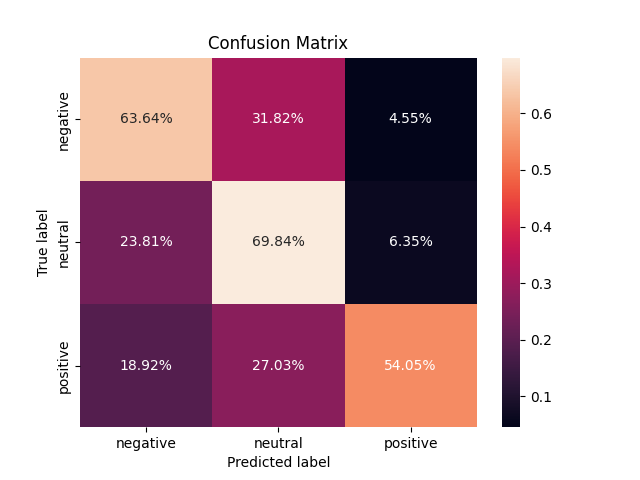
1. ábra A teszt adatbázis tévesztési mátrixa a BERT modell alapján
A gazdasági hangulat-elemzéshez előzetesen betanított magyar nyelvű BERT modellt alkalmaztunk, amelyet szekvencia osztályozásra finomítottunk. A bemeneti adatok gazdasági cikkek mondatait tartalmazzák, míg a kimenet negatív, pozitív vagy semleges hangulatot becsül. A modell megítélésünk szerint kiváló eredményeket ér el, amit a tévesztési mátrix átlójában lévő magas értékek is mutatnak, jelezve a helyes becsléseket. Független tesztadatbázison a modell mintegy 70% pontosságot ért el.
2. ábra Hasonlóság mérése a GDP és a transzformer alapú szentiment index alapján
A transzformer modell által klasszifikált cikkek hangulat értékei havi szintű aggregátumával kapott idősort összevetettük a GDP (év/év típusú, vagyis az előző év azonos időszakához viszonyított) értékeivel[1]. A hasonlóság igen szembetűnő, kiváltképp a válságos időszakokban, mint pl. 2009 és 2020. Ezek ígéretes eredmények és reményeink szerint hozzájárulhatnak az elemzői tevékenység hatékonyabbá tételéhez, informált döntések meghozatalához.
[1] Az összehasonlítás a dinamikus idővetemítés módszerével történt, ami lehetővé teszi két szekvencia hasonlóságának mérését, amik időben változhatnak. (Forrás: Wikipedia, link: Dinamikus idővetemítés – frwiki.wiki)